
Why workflow automation using AI is a progressively moving target — and how to keep hitting the bulls-eye using the GAINS framework
Connecting it all together

This is the fifth article in a five-part series on automating operational workflows with Gen AI models. The earlier articles addressed the foundational aspects — salami-slicing your transformation, choosing the right metrics, using the right forks, and ensuring consistency. If you haven’t read them, I would encourage you to do so. If you deeply care about this topic, they are worth your time.
An AI automation has been successfully rolled out in production. Congratulations!
Have you evaluated the possibility of it,
Not materially impacting any of the decisions?
Or worse, negatively impacting your operator productivity metrics?
Or terrible, degrading some of the outcome metrics?
And more importantly — what’s next on the to-do?
Read on. This is where taking a step back and bringing in system level perspectives becomes helpful.
The destination we are driving towards is end-to-end automation, with human judgement reserved for the most complex and nuanced decisions. We have already discussed in the first article why getting there is not a binary transition that can happen quickly. The reality is a multi-pronged transformation effort that involves complementing programs — Gen AI, workflow automation, ML-based automations, product transformations — all working together to get us to our destination.
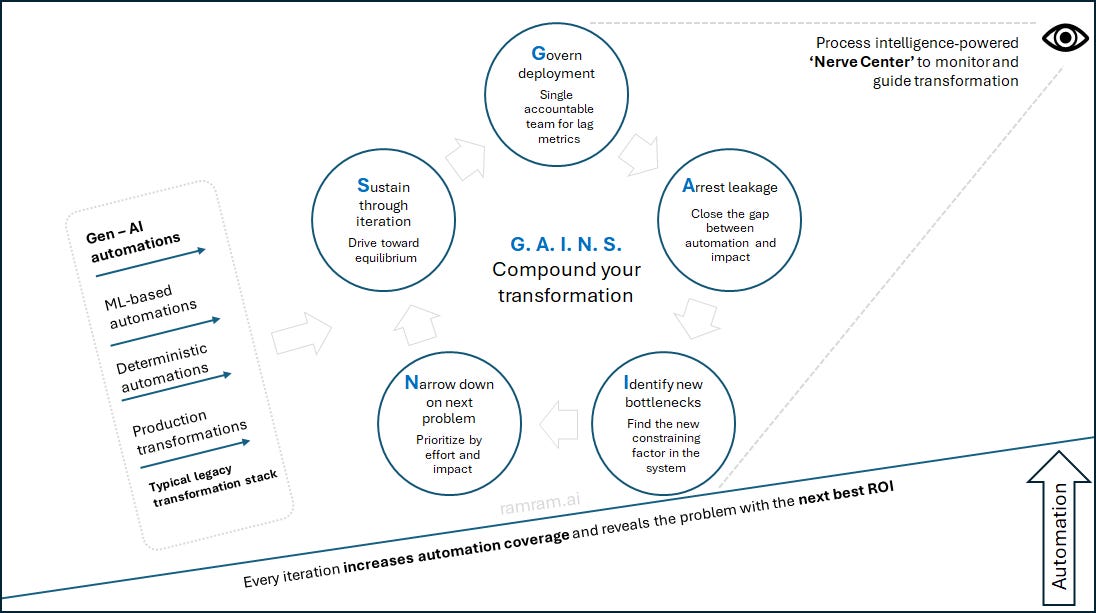
What we need is a systematic and flexible approach to organizing the people, process and systems as we iteratively execute towards our vision. Sharing with you the five-step GAINS framework that is helping us navigate the maze:
Govern deployment
Arrest leakage and demonstrate value
Identify the new bottlenecks
Narrow down on the next problem
Sustain through iteration
Let us discuss each of these steps in detail and our experience implementing them. Think of these steps as disciplines, not phases. Within a single initiative they often happen concurrently.
Govern deployment
Governance of Gen AI deployment is never at a fixed state. Think of governance as a progressive ladder — it starts ham-fisted with humans in the loop reviewing every decision, and gradually loosens as the solution demonstrates maturity through various metrics.
The governance plan usually depends on:
The maturity of the solution
The criticality of the decision
The redundancies and supervision baked into the system
Governance in Gen AI warrants more depth than a section can give. The one key takeaway from here is the need for a single accountable team. It is true that multiple teams need to work together to govern Gen AI models, and there are various aspects of governance. We have discussed ensuring and monitoring consistency in the fourth article. Typically the quality assurance teams do that on a periodic basis, and the data science team keeps monitoring the model for drift, throughput and token consumption.
Nevertheless, the overall accountability must rest with a single team — the custodians of the lag metric.
Let me explain that with our example of industry automation. The immediate benefits of automation are observed in operations through productivity improvement and cycle time reduction. However, if incorrect decisions are made along the way, it ultimately impacts the approval ratios and the portfolio mix — which are far more important in the pecking order of things. In our case, the accountability lies with the risk team, because the lag metrics I mentioned sit on their scorecard.
Once the governance guardrails are in place, the next step is to ensure realization of full potential.
Arrest leakage and demonstrate value
Arrest leakage
Leakage is the gap between the automation you built and the decisions it actually changes. A system can run at 95% accuracy and still deliver zero business impact if the downstream decision chain isn’t connected.
The disconnect is easy to overlook because you might be focused on the immediate outcome metrics discussed in article two, and not on the decisions themselves. It happens for trivial reasons — another job or agent not completing upstream decisions on time, or simple nomenclature mismatches that disrupt the automated flow of information.
Before you proceed any further, arrive at the total addressable impact. From the process repository, examine the downstream impact between the automation and the various decisions it eventually influences. At times, to realize the impact, it might also require you to make modifications to human actions in the workflow to accommodate this change. For each of those decisions, map the other inputs that need to be available at the time of decision making. Using this, you would be able to identify the potential addressable volume of decisions that could be automated. Ensure that you realize the addressable volume, and fix any leakages that stop you from doing that.
Demonstrate value
Once the leakage is fixed, demonstrate value of automation by quantifying the impact on system level metrics.
First, quantify the impact of automation on any of the operational metrics — cost, time, productivity, quality, customer satisfaction. Next, map the lag metrics and the trade-off metrics depending on the choice of impact metric, and demonstrate that they have stayed intact and not been impacted because of the automation. This is the intuition you’d build after spending time uncovering the full stack process intelligence.
This is an important step in establishing the credibility of automation, and to reassure the sponsors that it is indeed having a net positive impact on the metrics they can relate to.
In our case of SIC code automation, after the initial automation we realized that only one-fourth of the total addressable volume was getting impacted. On deeper probe, it gave us insights into the other decision chains that needed to be streamlined for us to realize the full benefits.
One aspect of value delivery worth flagging — counterintuitively, automation of SIC code decisions typically leads to a drop in operator productivity. Why? Among the multiple industry declines that happen, SIC code declines are relatively straightforward and do not take long. When a portion of that is eliminated from the manual decision pool, you are left with more complex decisions. This is the core idea of the third article — the art of winnowing. As a result, productivity decreases as an immediate aftermath. As humans and machines start working together, the work that gets done manually will be in a state of constant flux - so productivity scores need constant recalibration to reflect the nature manual tasks.
But it significantly reduces the time to decision, because the reduction in manual processing volume leads to shorter queues and better turnarounds. To complete the value articulation, we also monitor the quality of auto-decisions and the lag metrics like approval rates and portfolio mix of contracts, and ensure that they do not worsen.
This step marks the successful conclusion of that automation sprint. Let us answer the question of what to do next.
Identify the new bottlenecks
A bottleneck is a step that constrains the whole flow. The speed of the bottleneck is slower than the speed of the queue, which is why you will see a pileup in front of it. Once a bottleneck is automated, the dynamics change significantly — and a new constraining factor reveals itself.
There are various tools available in the realm of operations management to analytically study bottlenecks. Theory of constraints details out the various ways to identify them. Traditional lean solutions offer tools like takt time. More recently, process mining and task mining offer insightful patterns that can help us in this regard. The experienced operators intuitively know the bottlenecks in the system, and these tools help us corroborate that analytically.
This is an important but overlooked step. In the quest to complete automation, there is a tendency to pick a problem that is not the bottleneck. This, at best, results in minimal or no impact on system level metrics. At worst, it can compound the delays in the actual bottleneck even further. Goldratt has articulated this topic brilliantly in his book The Goal. A must read, if you haven’t already.
In our example, after the industry identification, we identified specific sub-processes related to bank statement analysis that are now constraining the system. We did that by studying a mix of task mining logs and decision ratios. In the next step, we will identify ways to narrow down on the bottleneck that gives the highest return on investment.
Narrow down on the next best action
Once the list of potential bottlenecks is identified, you need a systematic way to prioritize the next best action. Evaluating every bottleneck in terms of effort and impact is a good mental model to narrow down — assuming you have the necessary influence on the bottleneck.
On completing the SIC code, the system revealed two bottlenecks — bank statements and background checks. It was a straightforward comparison, because bank statements influenced far more decisions than background checks.
Now, with the bank statement checks, how do we prioritize among them? We started by mapping the volume of decisions taken using each check and the time required to do them. Next, we used a discrete event simulator to do a what-if analysis on the future state of the metrics when each of the checks are fully automated. Converting their impact to a common metric — like impact on decision cycle time — helped us narrow down on the next automation opportunity to focus on.
The cycle continues. We execute the identified opportunity through the steps outlined in the previous articles in the series.
Sustain through iteration
The framework described above offers enough structure and flexibility — a structure to keep our eyes on the ball, and the flexibility to adapt to changing circumstances. Neither too brittle nor too fluid.
When this approach is iterated, we will eventually reach an equilibrium — a state where the cases handled by humans involve the most nuanced and subjective decision calls. Depending on the maturity of the processes, the proportion of such cases will be small (ideally single digit percentages) and will have very little common among them. This becomes the ideal moment to surface opportunities for policy rationalization. Alternatively, if you have a high number of cases that involve human judgement, that is a reflection on your process maturity and it needs to be addressed on priority.
Following this framework helps ensure that every iteration gets us closer to the north star of complete automation, in the most optimal fashion.
Nerve Center: the GAINS monitor
The Nerve Center makes this entire framework operational rather than theoretical. Integrate your volumes, decisions, process transitions and task mining logs into a single platform, and two things become possible in real time — the system level view that drives steps G, A and I, and a Gen AI skill that automates steps N and S (credits to my collegue Adithya for reccomending this) . We are building this in Celonis, though an open-source stack would serve equally well. It will be our compass guiding us in the automation journey.
This brings us to the end of the five-part series on the learnings from our Gen AI transformation — a framework that is being refined as we go. Sharing it as a working approach rather than a tested formula. With this approach, we have a way to think big, start small and scale fast — in the most optimal way.
If you have stayed with me this far, thank you. I wish you the best in your transformation journey as you compound your GAINS.